Plans for the Duke University FinTech Trading Competition
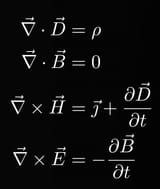
How far can trading only a single Forex pair get me?
What is the competition all about?
From the main website, the competition states:
"The Duke FinTech Trading Competition is a 3-month long event in which student traders from around the world create paper trading accounts at Interactive Brokers and trade anything they want, including stocks, bonds, options, futures, currencies, crypto, and any of the other products offered by Interactive Brokers."
The competition ranks you first by how high your sharpe ratio is, followed then by your geometric mean return.
It is a good way to introduce students into trying to factor in risk, and not thinking that high return from betting on something == investment skill.
Why I decided to join
While I was waiting for my CFA Level 1 results, I decided to fill in the gap with some extra supplementary learning. The day after my exam, I was scrolling through LinkedIn and I found someone mention this competition.
When I saw that they were using Interactive Brokers, I was exited because I am slightly familiar with the application, and always wanted to learn how to use its Python API.
So I joined the competition late, in the hopes that I get to use it as an excuse to learn a decently complex system under a competition timeline.
My plan for the competition
An interesting thing that I have noticed for the Interactive Brokers (IBKR) Paper Account is that if you want a live data feed for stocks, you are delayed by 15 minutes!
Apparently, the only assets that the free paper trading account allows for free, non-subscription, live streaming of data are:
- Forex
- Metals
- US Bonds
US Bonds required too much calculations for my low performance laptop. Metals are currently very volatile due to recent world events that I did not feel confident in creating a model robust enough to capture that.
So I was left with Forex.
I knew High Frequency Trading in Forex would mean that there is a low chance of me making any sort of positive return, but I was more interested in the data collection and implementation.
Hypothesis: The strength of a country's currency reflects all fundamental macro variables
My hypothesis assumes that if I get a large enough list of currency pairs, (both major and minor currency pairs) then I can find a volatility/return pattern without the need to pull the macro details myself.
Thus I decided to pull 6 month 5 second bar Open/High/Low/Close data for the following list of currencies:
- AUDUSD: Australian Dollar vs US Dollar (Aussie)
- EURGBP: Euro vs British Pound
- EURUSD: Euro vs US Dollar (Fiber)
- GBPUSD: British Pound vs US Dollar (Cable)
- USDCAD: US Dollar vs Canadian Dollar (Loonie)
- USDCHF: US Dollar vs Swiss Franc (Swissie)
- USDCNH: US Dollar vs Chinese Yuan (Offshore Yuan)
- USDHKD: US Dollar vs Hong Kong Dollar
- USDJPY: US Dollar vs Japanese Yen
- USDMXN: US Dollar vs Mexican Peso
- USDSGD: US Dollar vs Singapore Dollar
My idea is to have a model that trains on these currency pairs that outputs weightings. We then take the 5 second ticker value at time = t, then use that to assume the volatility/return of a chosen ticker for time = t+1.
Model choice: Ridge Regression
Due to the time constraints, I wanted to choose a model that is very simple to understand and implement. At first I wanted to try a simple Linear Regression model, but as I was looking through the SciKit Learn docs, I found Ridge Regression.
Ridge Regression follows the same idea of choosing coefficients that minimize prediction error on the training data. With the only difference is that it adds an extra cost whenever coefficients get large, which pushes them to shrink toward zero.
My main thought is because the Forex pairs will have strong correlations with each other, the simple linear regression might just give me a zero for the weights. Whereas Ridge makes the model less sensitive to small changes in the data, which is important since forex pairs don't make large jumps.
Here is a general idea on how the code would look like:
input: X, y, alpha
split X, y into train and test
scale X_train
scale X_test using same scaler
fit Ridge on X_train and y_train with alpha
y_pred = predict X_test
compute error between y_test and y_predSimple pseudo-code for a Ridge Regression
Here is a simple explanation of each one:
- You start with the input data X, the target values y, and a strength setting called alpha. Alpha controls how strongly Ridge shrinks the coefficients.
input: X, y, alpha- You divide the data into two parts: one to teach the model, and one to check how well it learned.
split X, y into train and test- You standardize the training features so they are on a similar scale. This matters because Ridge penalizes coefficient size, and scaling keeps that penalty fair across variables.
scale X_train- You transform the test data using the exact same scaling rules from the training data, so the model sees the test set in the same format.
scale X_test using same scaler- You train the Ridge model on the training data. It learns relationships between inputs and outputs while also discouraging overly large coefficients.
fit Ridge on X_train and y_train with alpha- The trained model makes predictions on the test data it has never seen before.
y_pred = predict X_test- Finally, you compare the predictions to the real test values to see how accurate the model is. Usually R^2 or MSE (Mean Squared Error).
compute error between y_test and y_predStrategy
To keep things simple, I am planning on just using a simple Short/Long portfolio focusing only on USDCAD.
Adding in a rolling volatility of returns will allow me to include a simple regime detector, where I can mark low/medium/high volatility and have a trading multiplier based on the current volatility for position sizing.
Obvious limitations
The plan for this project is very simple. It makes the assumption that the data behaves in a homoskedastic environment where the current distribution is the correct and only distribution with fixed variance.
There is also the fact that High Frequency Trading of Forex will most likely eliminate any potential positive returns.
IBKR API and ib_async
I will use the Interactive Brokers API in python mixed in with IB_async.
The IBKR API is the official way for Python to talk to Interactive Brokers’ Trader Workstation or IB Gateway. It’s powerful, but the native setup is a bit more technical and callback-based.
The ib_async is a simpler Python library built on top of the IBKR API style. It gives you a clearer, more Pythonic interface, supports async workflows, and is easier to use in scripts.
We can compare how both the IBKR API and ib_async differ in python code below for getting live ticker data for USDCAD:
IBKR API:
from ibapi.client import EClient
from ibapi.wrapper import EWrapper
from ibapi.contract import Contract
import threading
class App(EWrapper, EClient):
def __init__(self):
EClient.__init__(self, self)
def tickPrice(self, reqId, tickType, price, attrib):
print("tickPrice:", reqId, tickType, price)
def tickSize(self, reqId, tickType, size):
print("tickSize:", reqId, tickType, size)
app = App()
app.connect("127.0.0.1", 7497, 1)
threading.Thread(target=app.run, daemon=True).start()
contract = Contract()
contract.symbol = "USDCAD"
contract.secType = "CASH"
contract.currency = "CAD"
contract.exchange = "IDEALPRO"
app.reqMktData(1, contract, "", False, False, [])ib_async:
from ib_async import *
ib = IB()
ib.connect("127.0.0.1", 7497, clientId=1)
contract = Forex("USDCAD")
ticker = ib.reqMktDataAsync(contract)
for _ in range(10):
ib.sleep(1)
print("bid:", ticker.bid, "ask:", ticker.ask, "last:", ticker.last)
ib.cancelMktData(contract)
ib.disconnect()The big takeaway of using ib_async are as follows:
- It avoids most of the callback boilerplate that the native IBKR API uses.
- Library is already integrated with python's asyncio package, where function calls like: 'reqMktData' can turn into 'reqMktDataAsync'. This allows you to have multiple assets that all concurrently pull data from the client without needing to create multiple client instances.
Concluding thoughts
I believe that this competition gives me a great opportunity to pick up IBKR and start playing around with it.
While the strategy and model implementation are very simple, it does allow me to learn the fundamental building blocks for a more complex version later.